




The mechanisms behind this function have been developed and expanded on when attempting to convert physical documents to digital ones over the past decade. OCR, or optical character recognition, is the backbone behind this necessary process. It’s the method that allows you to convert physical information into an easily editable digital format. As this technology is readily available and integrated into almost every popular system, understanding how this process works can help you leverage OCR to its fullest for your records and business projects. In this article, we’ll dive into what OCR scanning is and how it works. Furthermore, learn how you can use it to improve your business services.
What is OCR?
Optical character recognition is a software that converts printed documents into digital image files. It’s a copy machine that turns a scanned document into readable, editable PDFs that you can edit and share. It works to digitize text, allowing you to present, edit, store, and search it. Today, this assists in many automated business tasks such as invoicing and sales processing. It is a valuable tool for areas where you can’t create an electronic document digitally.
A Brief History of Optical Character Recognition
Emanuel Goldberg originally developed OCR during World War I. Its roots trace back to telegraphy, where he invented a machine to read and convert characters into telegraphic code. During the 1920s, most businesses were using microfilming records. However, Goldberg’s invention used photoelectric cells to perform pattern recognition with the help of a movie projector called the Statistical Machine. It was considered the first step towards automation and record keeping. This invention was patented and eventually acquired by IBM, eventually leading to today’s printers, scanners, and electronic documents.
Today, many OCR service providers offer this technology through cloud service APIs. Therefore, it can recognize most characters and fonts with high accuracy. It remains the tool of choice for converting paper invoices to extractable data and provides more protection than paper alone.
How Does OCR Work?
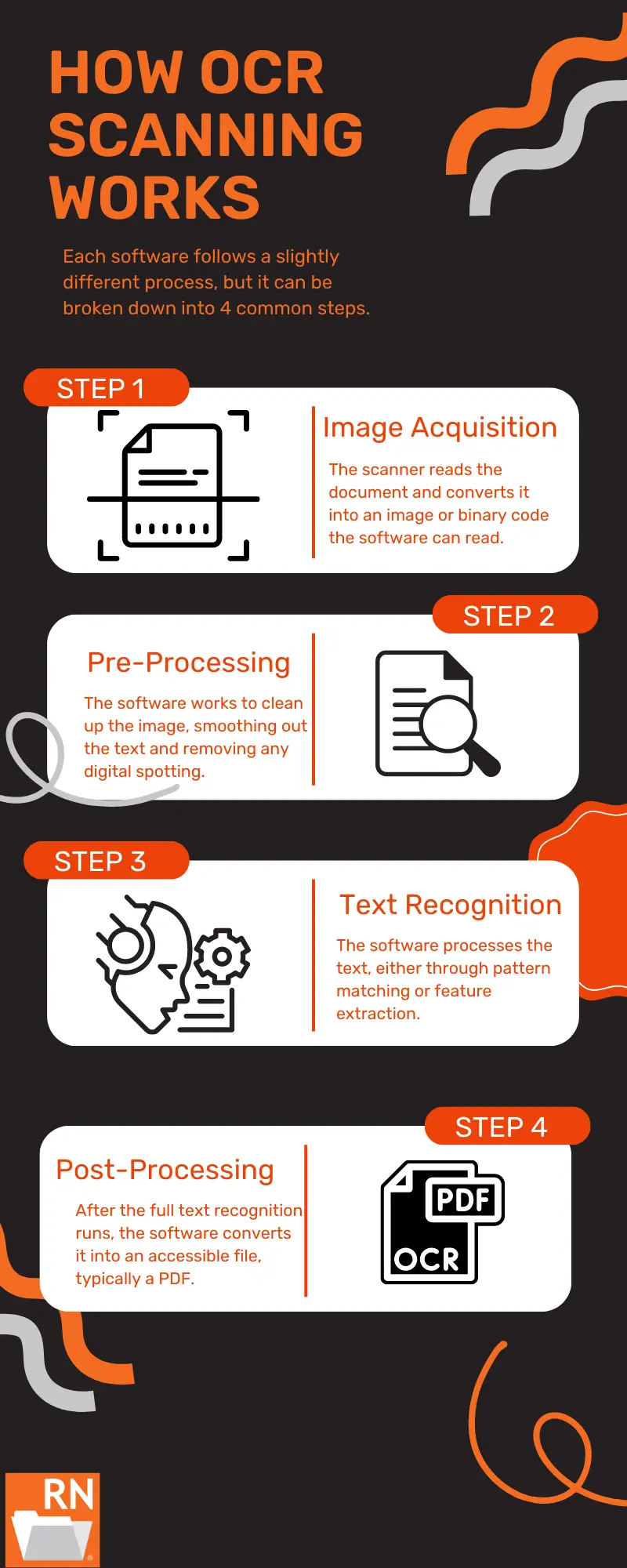
The process that OCR uses to extract data from documents and images involves many sequencing and precise steps.
- Upload: It starts with uploading the image or document containing the desired text. Generally, the clarity and quality of the document or image play a role in how accurately the OCR software can scan and digitize the data. You must scan the raw data using a scanner for it to begin processing.
- Preprocessing: The preprocessing stage enhances the data quality by cleaning up images and cropping areas of the images and text files to help avoid mistakes during the text recognition step. Preprocessing works to reduce the risk of errors by rotating, cropping, image scaling to a specific resolution, noise removal, skew correction, and binarization (black and white contrasting) to enhance the image for its next step better.
- Text Recognition with Pattern Recognition: This essential stage compares the visual patterns of the input text with its database of known characters and symbols. The system consults its database of known patterns, even handling different fonts to identify patterns in documents and images.
- Feature Extraction: From there, OCR works with complicated algorithms to extract and refine the characters for better accuracy. This step is typically for documents and images with handwritten characters. For example, it analyzes the characteristics of those found on receipts, contracts, and tax forms accurately. It can be used to analyze slants, loops, intersections, and other facets of handwriting to improve its results.
- Post-Processing: The post-processing stage involves correcting any errors in the document or image, analyzing its contents, and assembling the characters into coherent words and sentences. This last stage works as a finalizing stage to address any inaccuracies and misinterpretations that may have been missed in the previous steps. After that, this process would continue until the OCR systems considered the document or image fully scanned.
The Types of OCR Technology Used Today
While the process of OCR is similar across most systems, there are various approaches to OCR technology. These different types cater to specific applications, depending on the purpose and context of your business needs. Here’s a short list of some of the most commonly developed OCR methods used in today’s scanners and printers:
- Pattern Recognition OCR: As the most common type, it uses advanced algorithms to identify visual patterns in characters, and it’s considered ideal for high-precision applications such as financial audits and legal documents.
- Feature Extraction OCR: This method analyzes specific features of each character, such as lines and curves, to handle diverse fonts and styles. In these cases, it’s considered an updated, improved version of pattern recognition OCR.
- Intelligent Character Recognition: Intelligence character recognition focuses on human input-like processing for handwritten characters, such as handwritten letters, signatures, and other forms of unique characters, and it goes beyond the use of standard OCR for these cases.
- Optical Mark Recognition: This type of OCR focuses on identifying data marks within documents and images, such as checkboxes and bubbles often found in surveys, exams, and questionnaires. It’s specifically designed to interpret human-marked data for these specific cases.
- Optical Word Recognition: Optical Word Recognition focuses on whole words as data instead of characters for documents with condensed information, such as newspapers and magazines. It works to improve the content extraction process and the efficiency of its scanning abilities.
- Mobile OCR: This type of OCR works with smartphone cameras to capture text on the go and digitize documents and images. It removes the need for extra equipment by working with the phone’s processor for data extraction and digitalization.
What Type of Scanners Provide OCR For Businesses?

Most cases of OCR are used for converting printed documents to digital text documents. For instance, Microsoft Word and Google Docs. It’s considered a hidden technology in most systems today and in reality, is most often included in today’s printers and scanners. If you’re wondering what types of machines include this technology, here’s a brief overview of the available printers and scanners that have OCR software included:
- Document Management Scanners: These scanners are ideal for those needing higher print speeds and automatic document feeders to accommodate large volumes of scans.
- Photo Scanners: Photo scanners are used for high-quality images and don’t often require many scans to perform well.
- All-in-One Printers: All-in-one printers can print, copy, and fax documents and images using OCR. You can use these for personal use or integrated into a business. However, they lack the capacity to handle large amounts of paper input for scanning and printing.
The Benefits of OCR For Your Company
OCR can bring many useful benefits to your business. This is especially if you want to build record management systems and disaster recovery plans to protect your data. Optical character recognition software used in high-end scanners and printers can be an essential component of any growing business looking to improve its efficiency and financial input, as it has been incorporated into today’s economy. Some of the benefits that you can find with this technology include:
Improve Efficiency
OCR works to automate the data entry process. Therefore, it eliminates the need for manual data entry, and helps reduce the resources spent on these tasks. Automating and digitizing your documents, records, and images can improve the efficiency of your business.
Save on Costs
It’s an excellent cost saver, as it streamlines the process and removes the dependence on manual data entry. Many cloud-based API servers, printing and scanning companies, and similar services can typically offer better subscription rates. Moreover, they offer bulk purchasing deals on OCR scanning devices, resulting in substantial business cost savings.
No Manual Entry
One of OCR’s biggest benefits is its ability to remove the need for manual entries from your employees’ workflow. It speeds up the data entry process and reduces the time for specific tasks, contributing to your business’s overall productivity.
Reduce Human Errors
Automating your data entries helps reduce the chance of errors. This is due to OCR’s high accuracy rate when analyzing and processing information through its collected datasets and algorithms. These automated processes have similar accuracy rates to human data entry. However, they remove the manual time, labor, and potential for human error from the equation.
Automate Your Workspace
Whether you invest in finances, work within the healthcare industry, act as a legal advisor, or work in other industries that require extensive data collection and use, having OCR in your business management can help improve the speed and accuracy of your workflow and keep your data safe.
Invest in OCR Scanning with Record Nations
If you’re looking to partner and work with scanning providers for your business, Record Nations can connect you with the services you need to help your business thrive. Whether you’re looking to connect locally, request a quote for an all-inclusive scanning service, or just want to learn more about your options, you can connect with our team by calling (866) 385-3706 or fill out the form below to see what our providers can do for you.






